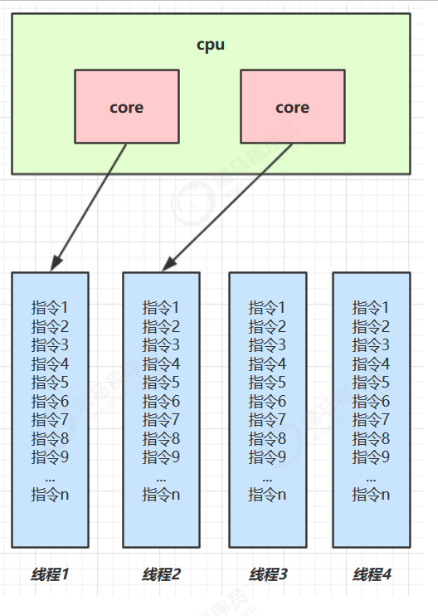
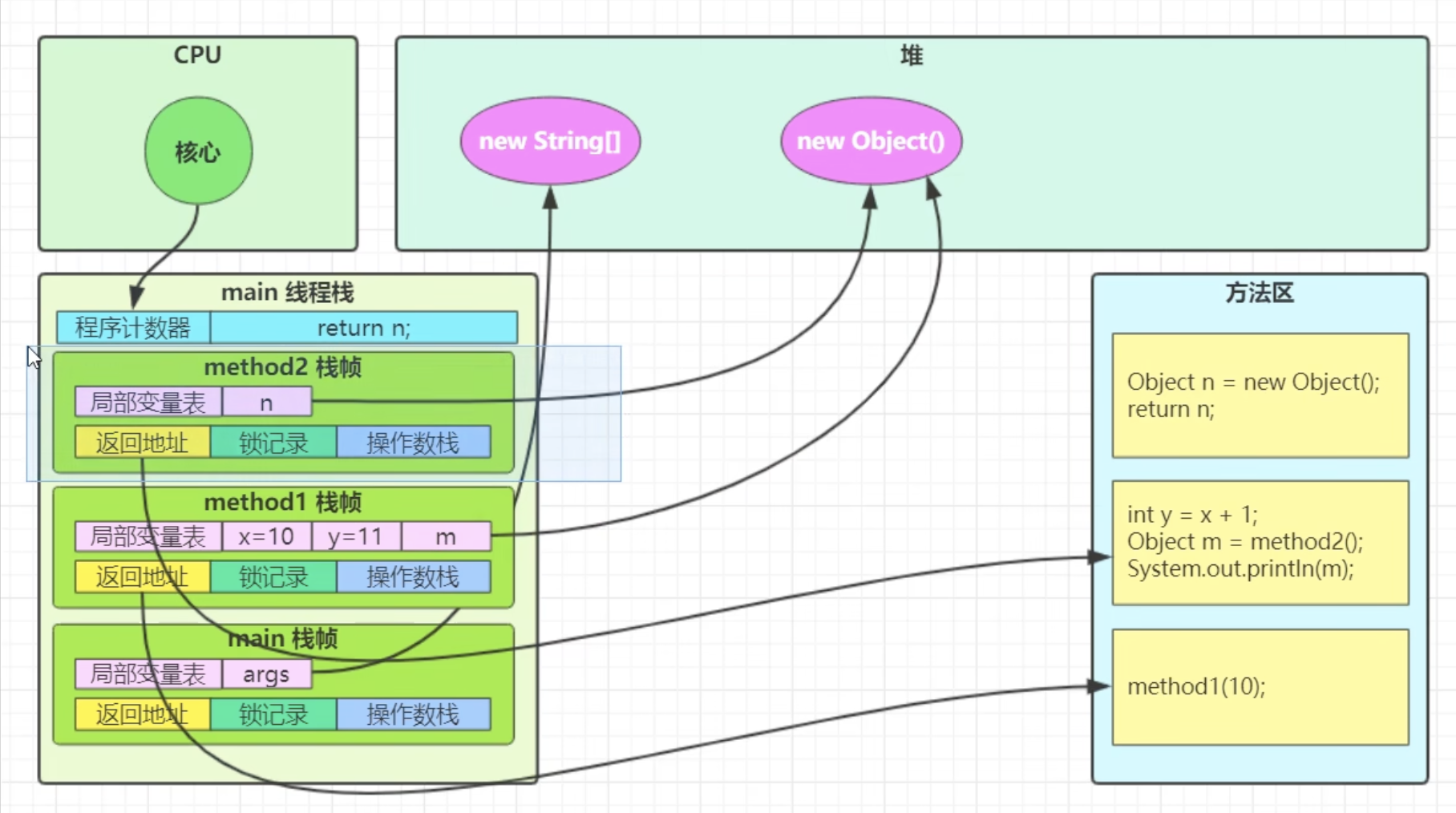
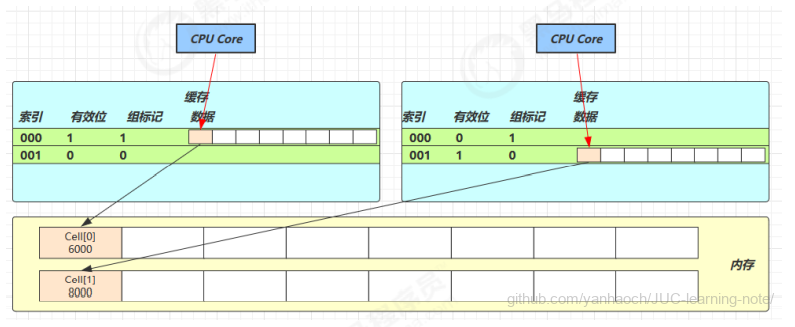
概述
为什么学
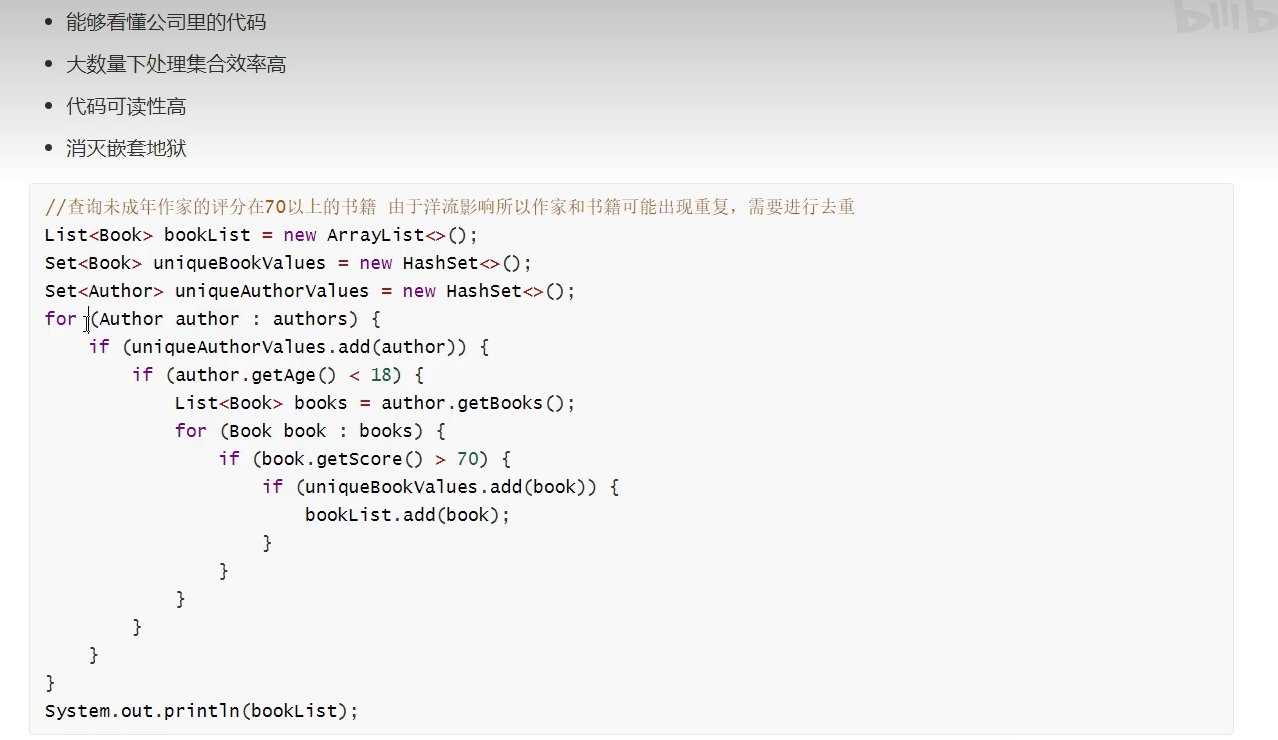
函数式编程思想

Lambda 表达式
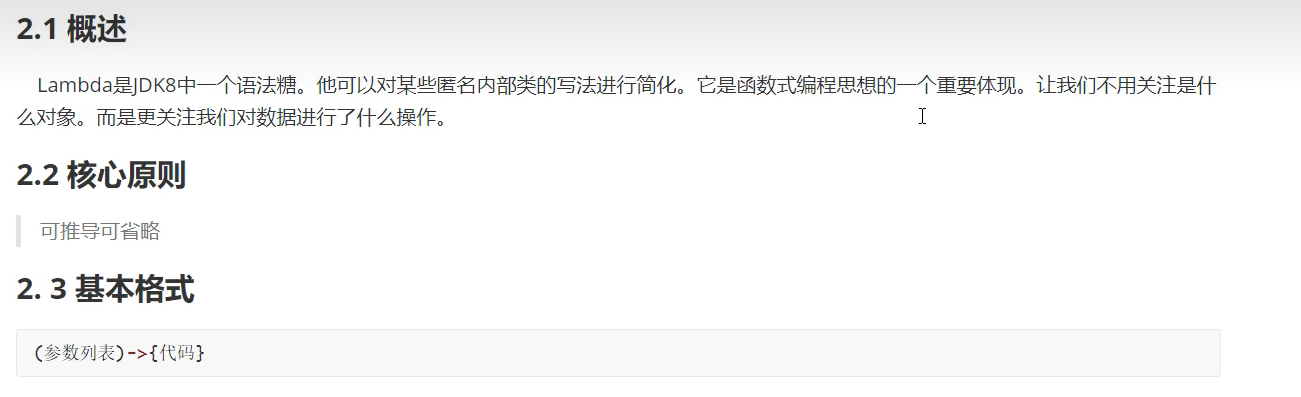
概述
使用情况
- 参数为一个接口,并且只有一个抽象方法 (不包含抽象方法|)
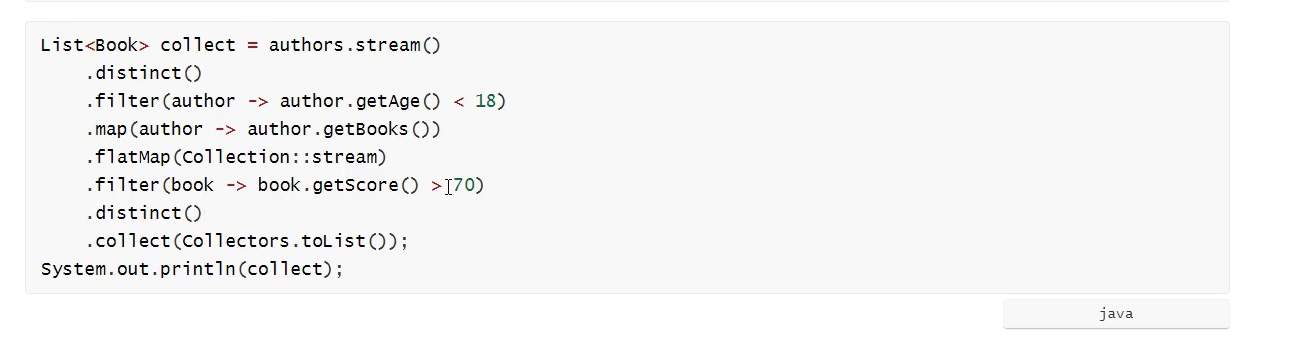
- 例如:

例
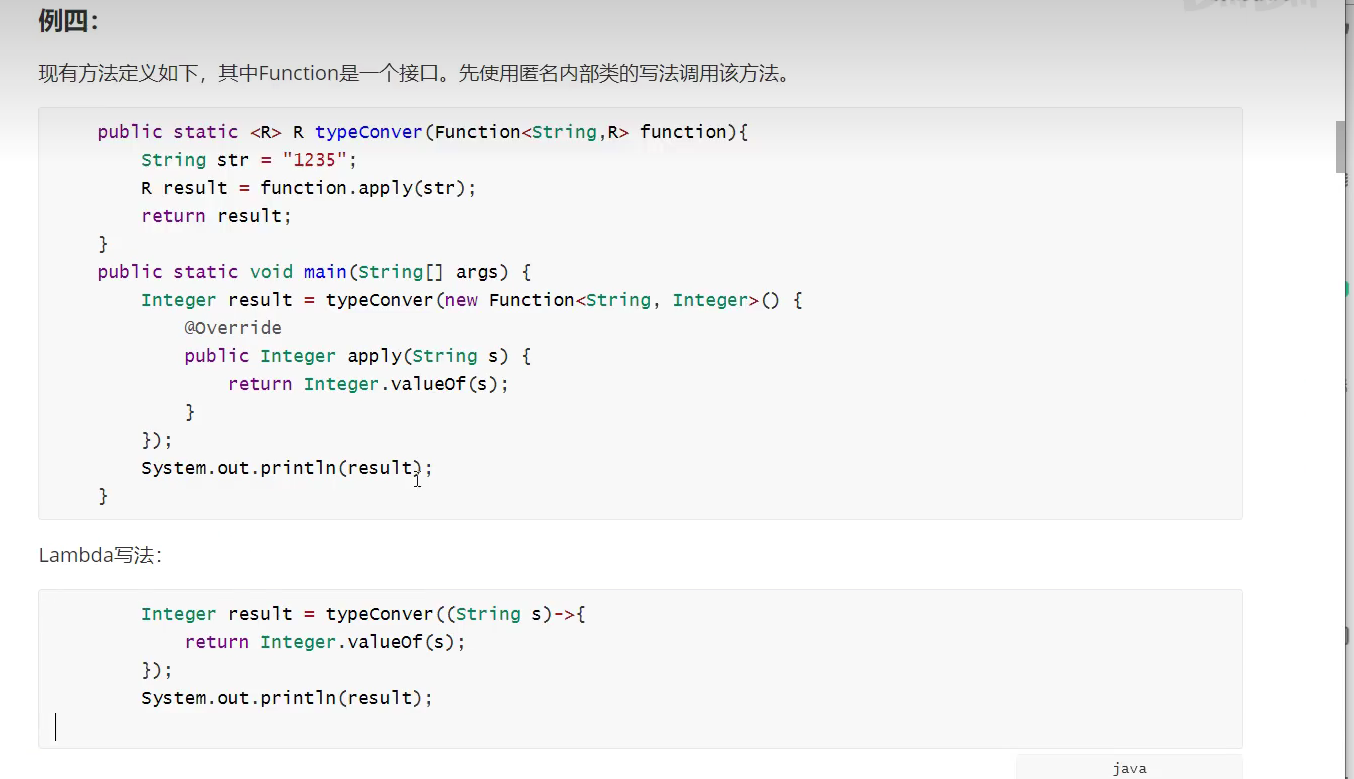
例 1
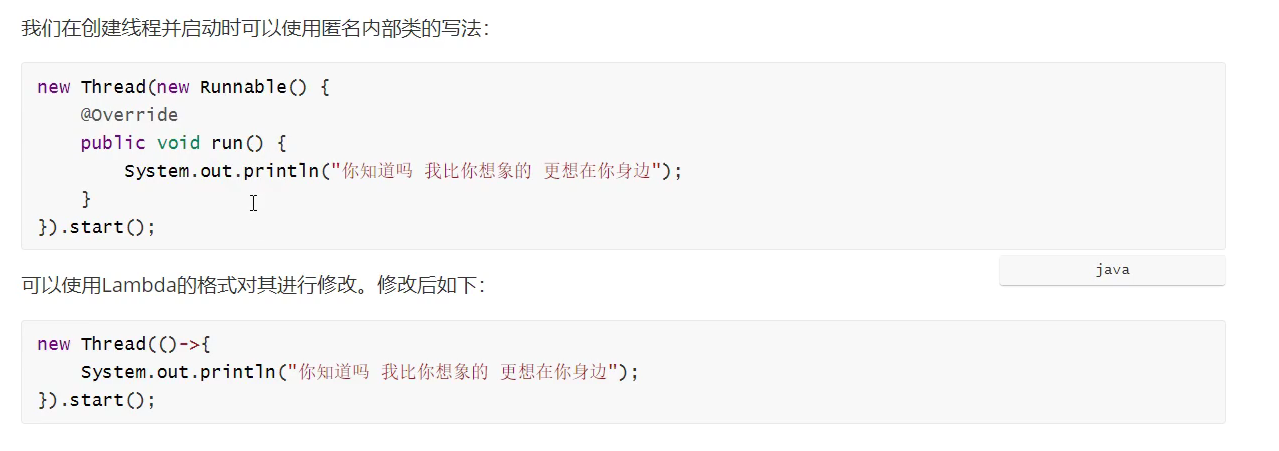
例 2
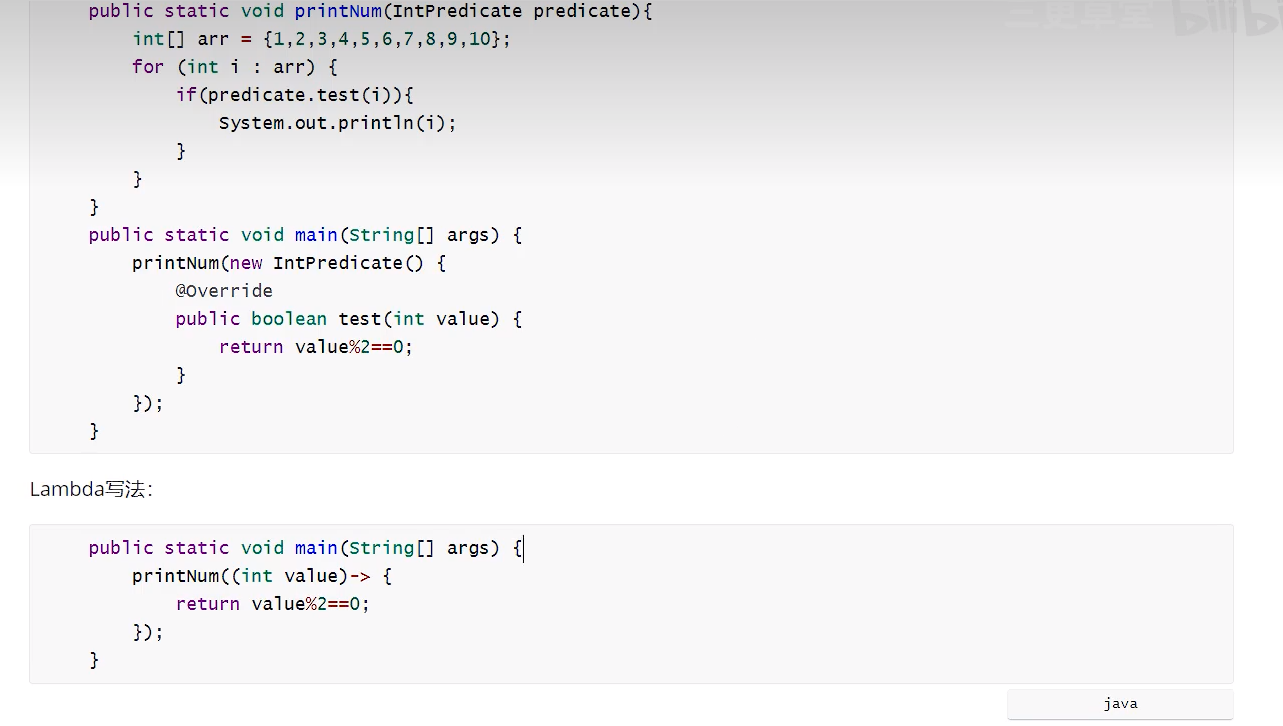
例 4
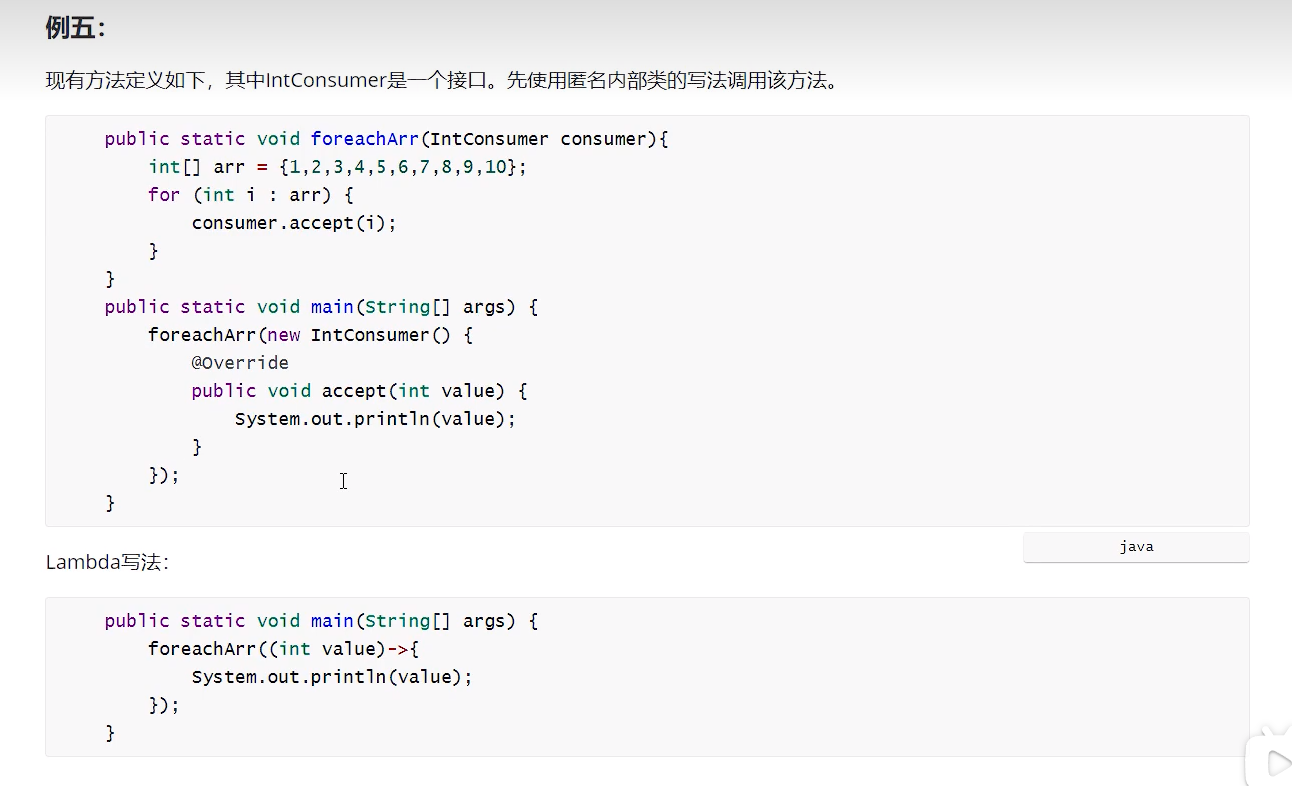
例 5
✨ 省略规则

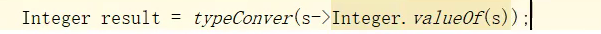


Stream 流
https://www.bilibili.com/video/BV1Gh41187uR?p=12&spm_id_from=pageDriver&vd_source=30924cc6debe913490fb34d7e3b62fdd
概述

初始化工程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| public class StreamDemo {
public static void main(String[] args) {
List<Author> authors = getAuthors();
System.out.println(authors);
}
private static List<Author> getAuthors() {
Author author = new Author(1L, "蒙多", 33, "一个从菜刀中明悟哲理的祖安人", null);
Author author2 = new Author(2L, "亚拉索", 33, "狂风也追逐不上他的思考速度", null);
Author author3 = new Author(3L, "易", 14, "是这个世界在限制他的思维", null);
Author author4 = new Author(3L, "易", 14, "是这个世界在限制他的思维", null);
List<Book> books1 = new ArrayList<Book>();
List<Book> books2 = new ArrayList<Book>();
List<Book> books3 = new ArrayList<Book>();
books1.add(new Book(1L, "西游记", "冒险,奇幻", 90, "西天取经"));
books2.add(new Book(2L, "三国演义", "社会", 99, "三国演义"));
books3.add(new Book(3L, "红楼梦", "abc", 70, "ggg"));
author.setBooks(books1);
author2.setBooks(books2);
author3.setBooks(books3);
author4.setBooks(books3);
return new ArrayList<>(Arrays.asList(author, author2, author3, author4));
}
}
|
快速入门
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
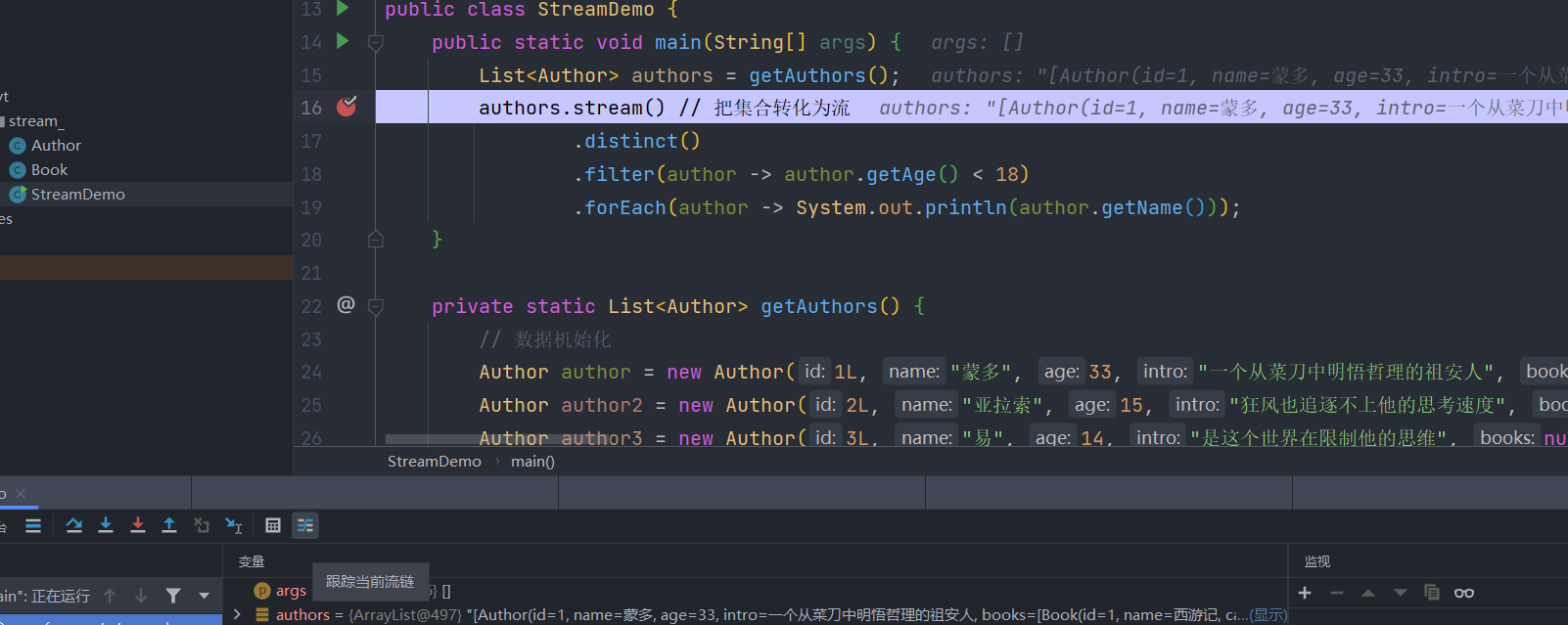
| List<Author> authors = getAuthors();
authors.stream()
.distinct()
.filter(new Predicate<Author>() {
@Override
public boolean test(Author author) {
return author.getAge() < 18;
}
})
.forEach(new Consumer<Author>() {
@Override
public void accept(Author author) {
System.out.println(author.getName());
}
});
|
1
2
3
4
| authors.stream()
.distinct()
.filter(author -> author.getAge() < 18)
.forEach(author -> System.out.println(author.getName()));
|
dubug 分析
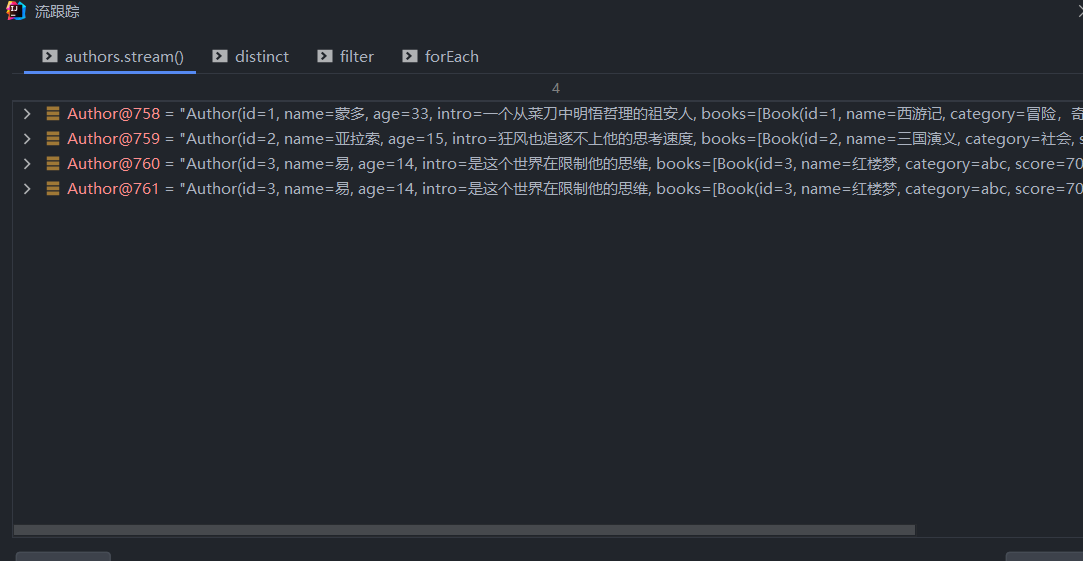
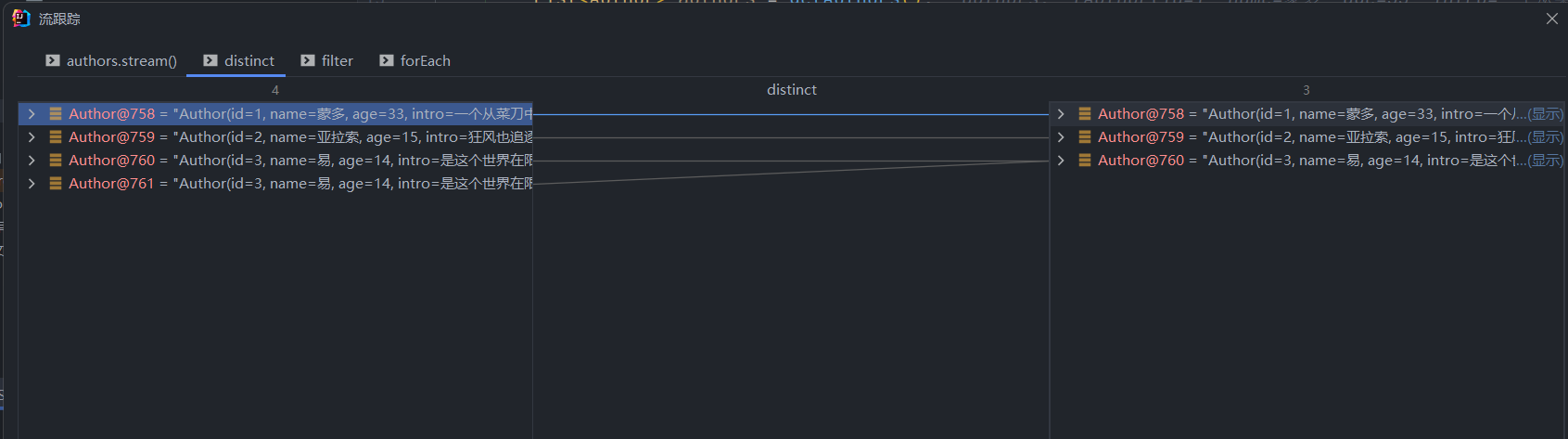
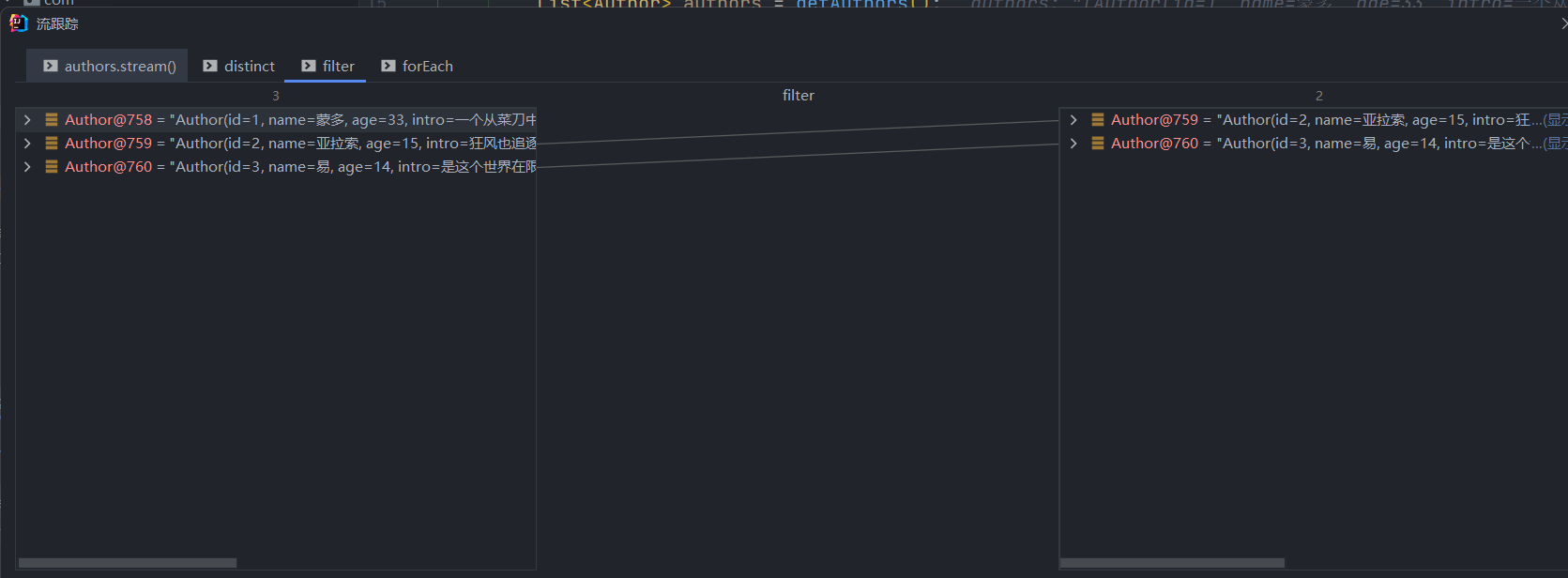
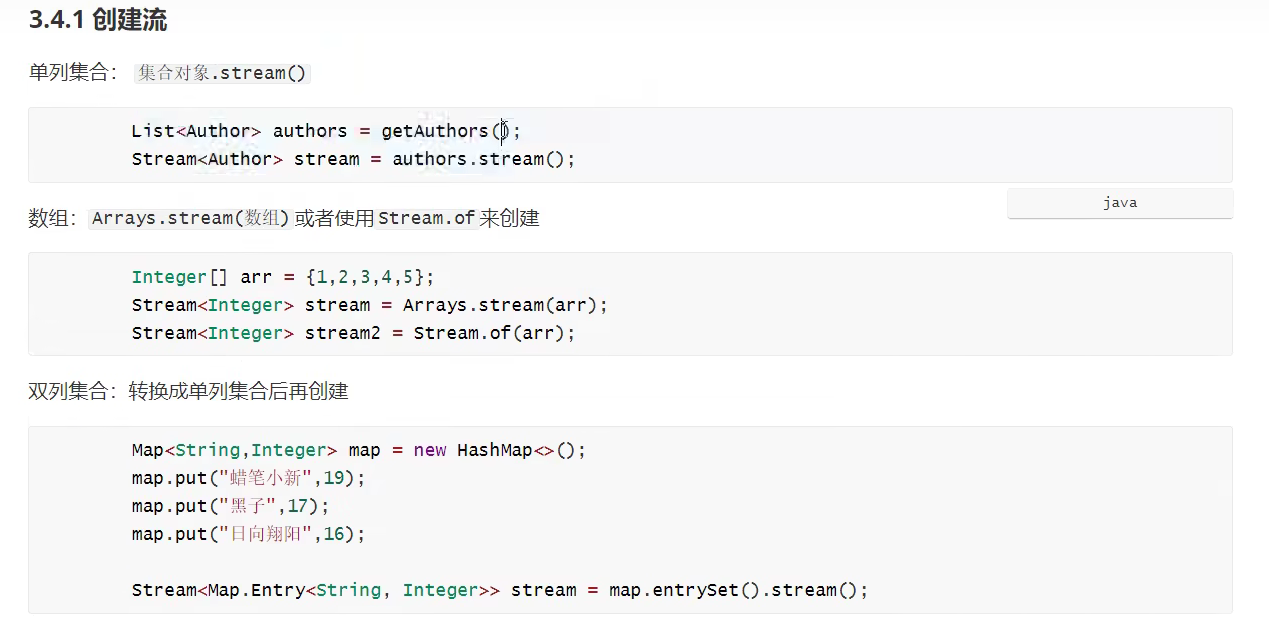
创建流
1
2
3
4
5
6
7
8
9
| @Test
private static void test02() {
Integer[] arr = {1, 2, 3 ,4 ,5, 5};
Stream<Integer> stream = Arrays.stream(arr);
stream.distinct()
.filter(item -> item > 4)
.forEach(item -> System.out.println(item));
}
|
1
2
3
4
5
6
7
8
9
10
11
12
|
@Test
public void testMap() {
HashMap<String, Integer> map = new HashMap<>();
map.put("诺手", 99);
map.put("亚索", 19);
map.put("ez", 32);
Set<Map.Entry<String, Integer>> entries = map.entrySet();
Stream<Map.Entry<String, Integer>> stream = entries.stream();
stream.filter(item -> item.getValue() > 90)
.forEach(item -> System.out.println(item.getValue()));
}
|
中间操作
filter
1
2
3
4
5
6
7
8
9
10
11
| @Test
void testFilter() {
List<Author> authors = getAuthors();
authors.stream()
.filter(item -> item.getName().length() > 1)
.forEach(item -> System.out.println(item.getName()));
}
|
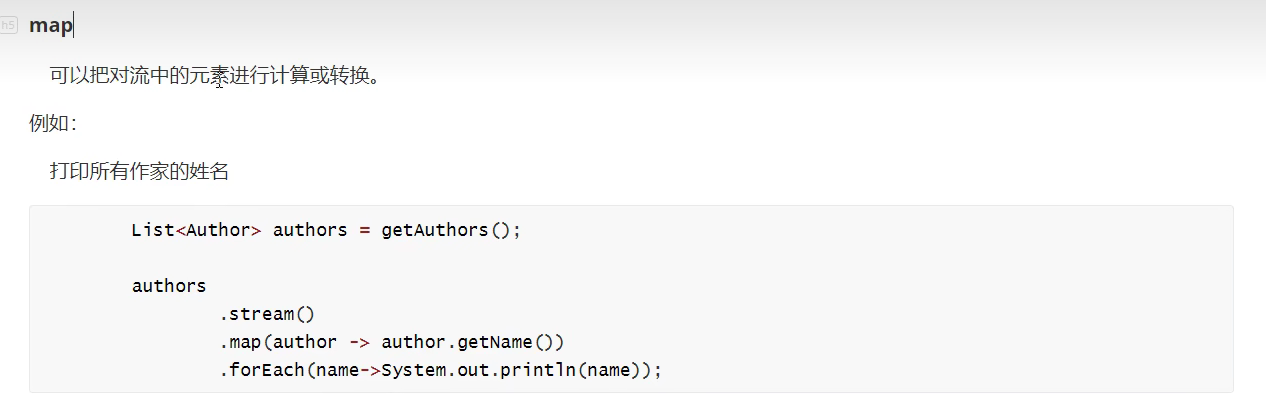
✨map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
@Test
void testMap() {
List<Author> authors = getAuthors();
authors.stream()
.map(new Function<Author, String>() {
@Override
public String apply(Author author) {
return author.getName();
}
})
.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
}
|
1
2
3
| authors.stream()
.map(author -> author.getName())
.forEach(s -> System.out.println(s));
|
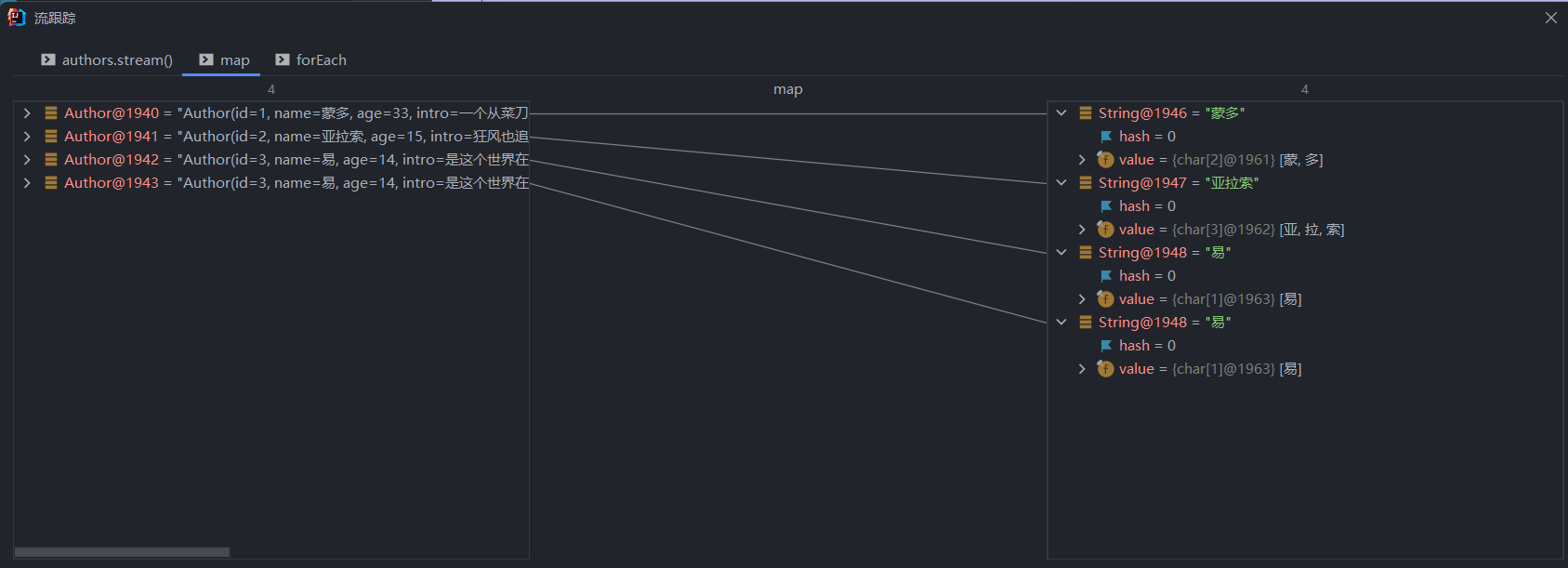
- debug map
- 把作家的姓名作为流返回
- 流中的数据类型从 Author 转为 String
distinct
1
2
3
4
5
6
7
8
9
10
11
12
13
|
@Test
void testsort() {
List<Author> authors = getAuthors();
authors.stream()
.distinct()
.sorted((o1, o2) -> o2.getAge() - o1.getAge())
.forEach(item -> System.out.println(item.getAge()));
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| @Data
@NoArgsConstructor
@AllArgsConstructor
@EqualsAndHashCode
public class Author implements Comparable<Author>{
private Long id;
private String name;
private Integer age;
private String intro;
private List<Book> books;
@Override
public int compareTo(Author o) {
return this.getAge() - o.getAge();
}
}
|
Limit
1
2
3
4
5
6
7
8
9
10
|
@Test
public void testLimit() {
List<Author> authors = getAuthors();
authors.stream()
.distinct()
.sorted()
.limit(2)
.forEach(item -> System.out.println(item.getAge()));
}
|
skip
1
2
3
4
5
6
7
8
9
10
11
12
13
| @Test
public void testSkip() {
List<Author> authors = getAuthors();
authors.stream()
.distinct()
.sorted()
.skip(1)
.forEach(item -> System.out.println(item.getAge()));
}
|
flatMap
- map 只能将一个对象转为另一个对象作为流中的元素
- flatMap 可以一个对象转为另多个对象作为流中的元素
- 优化前
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
@Test
void testFlatMap() {
List<Author> authors = getAuthors();
authors.stream()
.flatMap(new Function<Author, Stream<Book>>() {
@Override
public Stream<Book> apply(Author author) {
return author.getBooks().stream();
}
})
.distinct()
.forEach(item -> System.out.println(item.getName()));
}
|
- 优化后
1
2
3
4
5
6
7
8
9
|
@Test
void testFlatMap() {
List<Author> authors = getAuthors();
authors.stream()
.flatMap(author -> author.getBooks().stream())
.distinct()
.forEach(item -> System.out.println(item.getName()));
}
|
debug 分析
authors流->books流
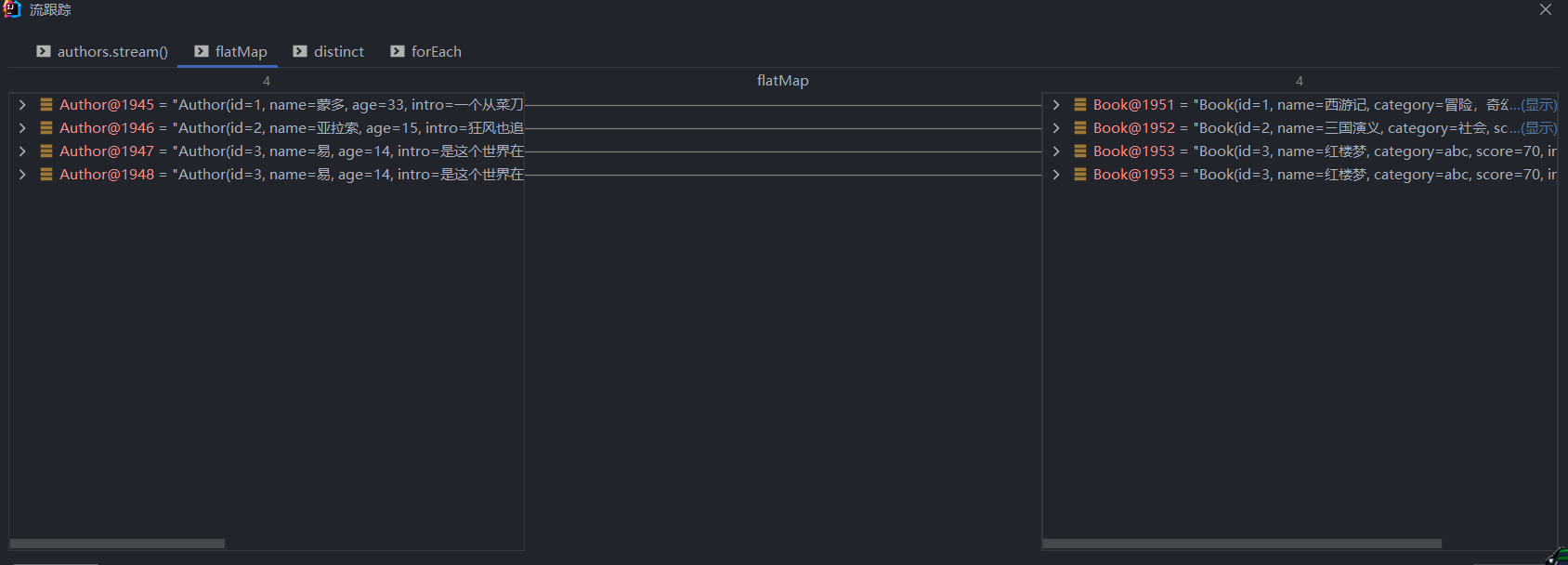
- 使用 split
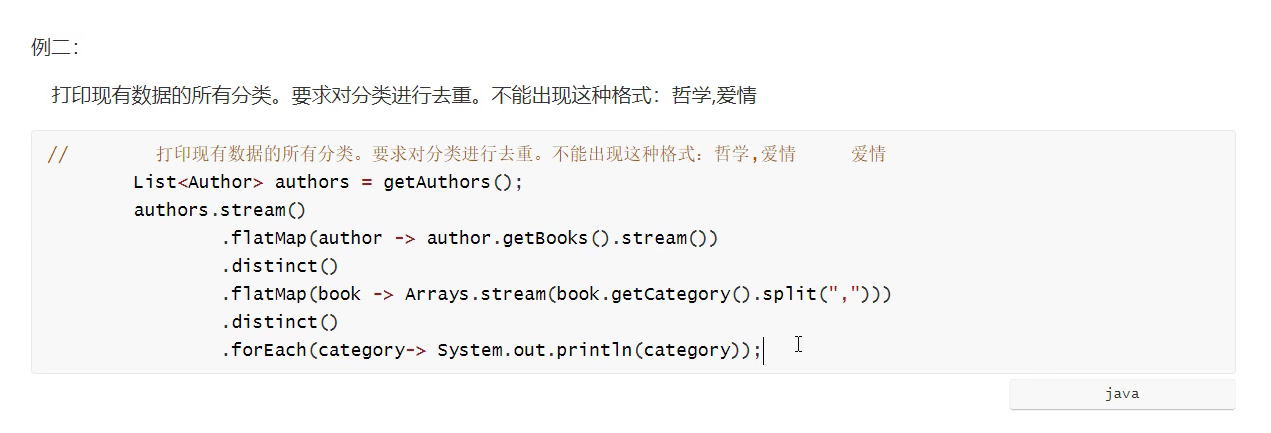
使用二
分类格式 xxx,xxx
- 要求获取所有分类,去重
- 先得到书籍的流
- 再得到分类数组(用 split 分开)
- 转为 stream
Arrays.stream
- 去重分类
终结操作
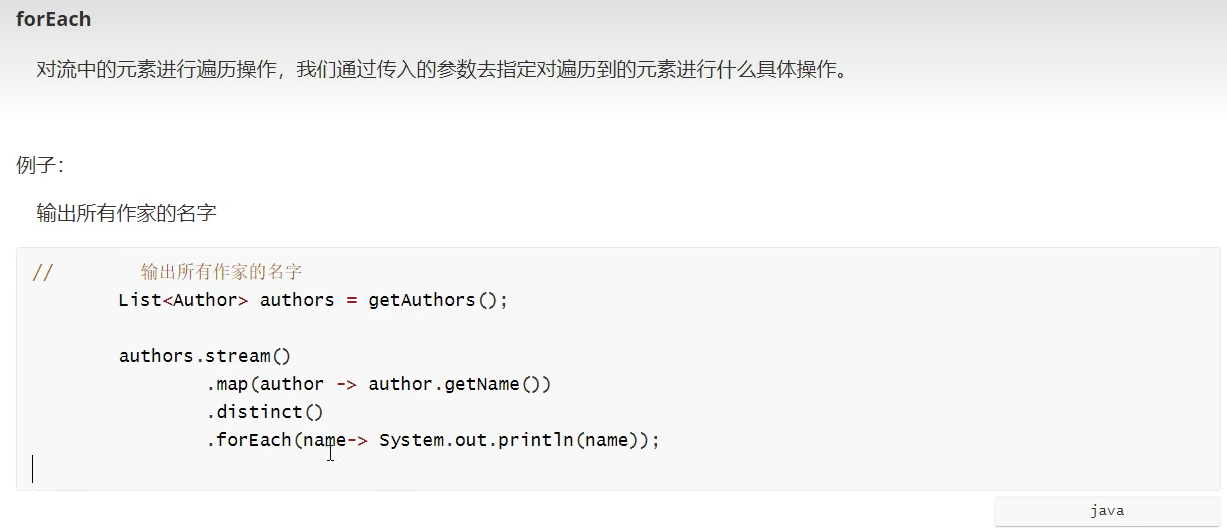
forEach
count
1
2
3
4
5
6
7
8
9
10
11
12
|
@Test
void testCount() {
List<Author> authors = getAuthors();
long count = authors.stream()
.flatMap(author -> author.getBooks().stream())
.distinct()
.count();
System.out.println(count);
}
|
max&min
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
@Test
void testMaxAndMin() {
List<Author> authors = getAuthors();
Optional<Integer> max = authors.stream()
.flatMap(author -> author.getBooks().stream())
.map(book -> book.getScore())
.max((b1, b2) -> b1 - b2);
System.out.println(max.get());
}
@Test
void testMaxAndMin() {
List<Author> authors = getAuthors();
Optional<Integer> min = authors.stream()
.flatMap(author -> author.getBooks().stream())
.map(book -> book.getScore())
.min((b1, b2) -> b1 - b2);
System.out.println(min.get());
}
|
✨collect
- 获取一个存放所有作者名字的 List 集合
1
2
3
4
5
6
7
8
9
|
@Test
void testCollect() {
List<Author> authors = getAuthors();
List<String> nameList = authors.stream()
.map(author -> author.getName())
.collect(Collectors.toList());
System.out.println(nameList);
}
|
- 获取一个所有书名的 set 集合
1
2
3
4
5
6
7
8
9
10
| @Test
void testSet() {
List<Author> authors = getAuthors();
Set<String> books = authors.stream()
.flatMap(author -> author.getBooks().stream())
.map(book -> book.getName())
.collect(Collectors.toSet());
System.out.println(books);
}
|
- 获取一个 Map 集合, map 的 key 为作者名,value 为
List<Book>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| @Test
void testMap() {
List<Author> authors = getAuthors();
Map<String, List<Book>> map = authors.stream()
.distinct()
.collect(Collectors.toMap(new Function<Author, String>() {
@Override
public String apply(Author author) {
return author.getName();
}
}, new Function<Author, List<Book>>() {
@Override
public List<Book> apply(Author author) {
return author.getBooks();
}
}));
System.out.println(map);
}
@Test
void testMap() {
List<Author> authors = getAuthors();
Map<String, List<Book>> map = authors.stream()
.distinct()
.collect(Collectors.toMap(author -> author.getName(),
author -> author.getBooks()));
System.out.println(map);
}
|
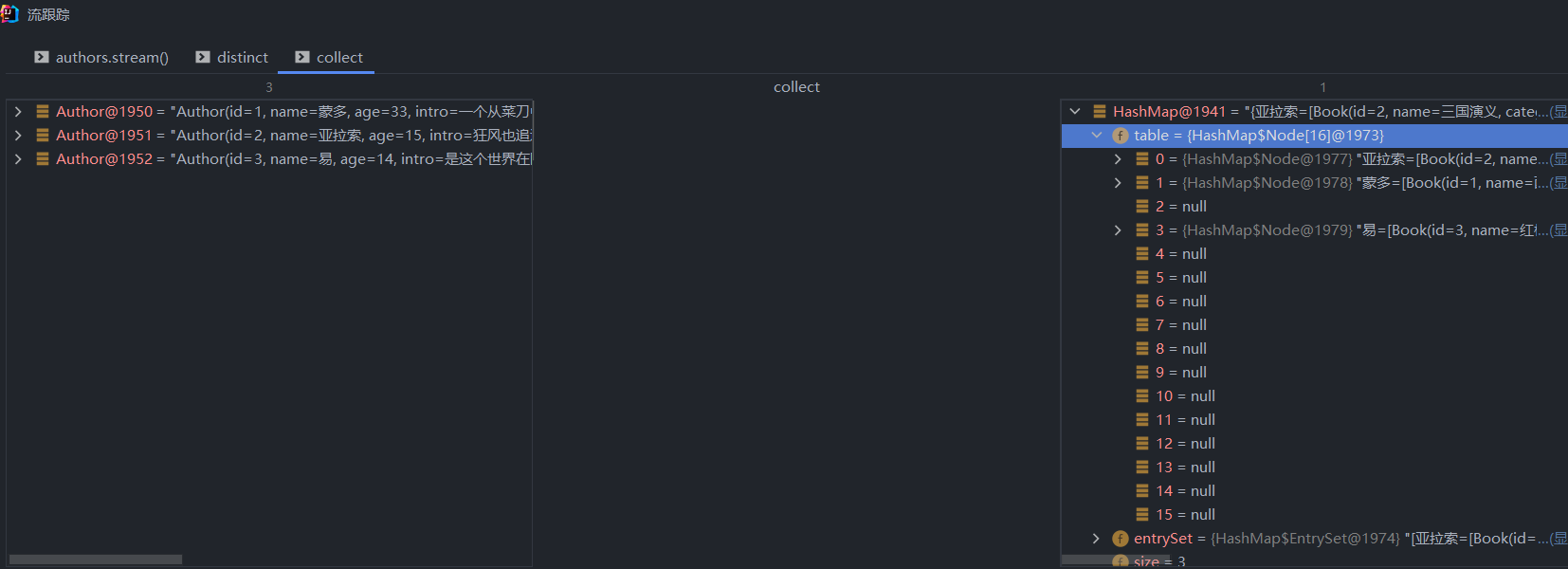
{亚拉索=[Book(id=2, name=三国演义, category=社会, score=99, intro=三国演义)], 蒙多=[Book(id=1, name=西游记, category=冒险,奇幻, score=90, intro=西天取经)], 易=[Book(id=3, name=红楼梦, category=哲学, score=70, intro=ggg), Book(id=3, name=红楼梦, category=哲学, score=70, intro=ggg)]}
匹配
anyMatch
可以用来判断任意符合匹配条件的元素,结果为 boolean 类型
1
2
3
4
5
6
7
8
9
| @Test
void testAnyMatch() {
List<Author> authors = getAuthors();
boolean b = authors.stream()
.anyMatch(author -> author.getAge() > 29);
System.out.println(b);
}
|
allMatch
所有都匹配返回 true
1
2
3
4
5
6
7
8
|
@Test
void testAllMatch() {
List<Author> authors = getAuthors();
boolean b = authors.stream()
.allMatch(author -> author.getAge() > 18);
System.out.println(b);
}
|
noneMatch
判断是否都不符合
1
2
3
4
5
6
7
| @Test
void testNoneMatch() {
List<Author> authors = getAuthors();
boolean b = authors.stream()
.noneMatch(author -> author.getAge() > 100);
System.out.println(b);
}
|
查找
findAny
获取流中的任意元素,无法保证是第一个
1
2
3
4
5
6
7
8
9
| @Test
void TestFindAny() {
List<Author> authors = getAuthors();
Optional<Author> optionalAuthor = authors.stream()
.filter(author -> author.getAge() > 18)
.findAny();
optionalAuthor.ifPresent(author -> System.out.println(author));
}
|
findFirst
获取流中的第一个元素
1
2
3
4
5
6
7
8
| @Test
void testFindFirst() {
List<Author> authors = getAuthors();
Optional<Author> optionalFirst = authors.stream()
.sorted((o1, o2) -> o1.getAge() - o2.getAge())
.findFirst();
optionalFirst.ifPresent(author -> System.out.println(author.getAge()));
}
|
reduce
1
2
3
4
5
6
7
8
9
10
| @Test
void testreduce() {
List<Author> authors = getAuthors();
Integer sum = authors.stream()
.distinct()
.map(author -> author.getAge())
.reduce(0, (res, element) -> res + element);
System.out.println(sum);
}
|
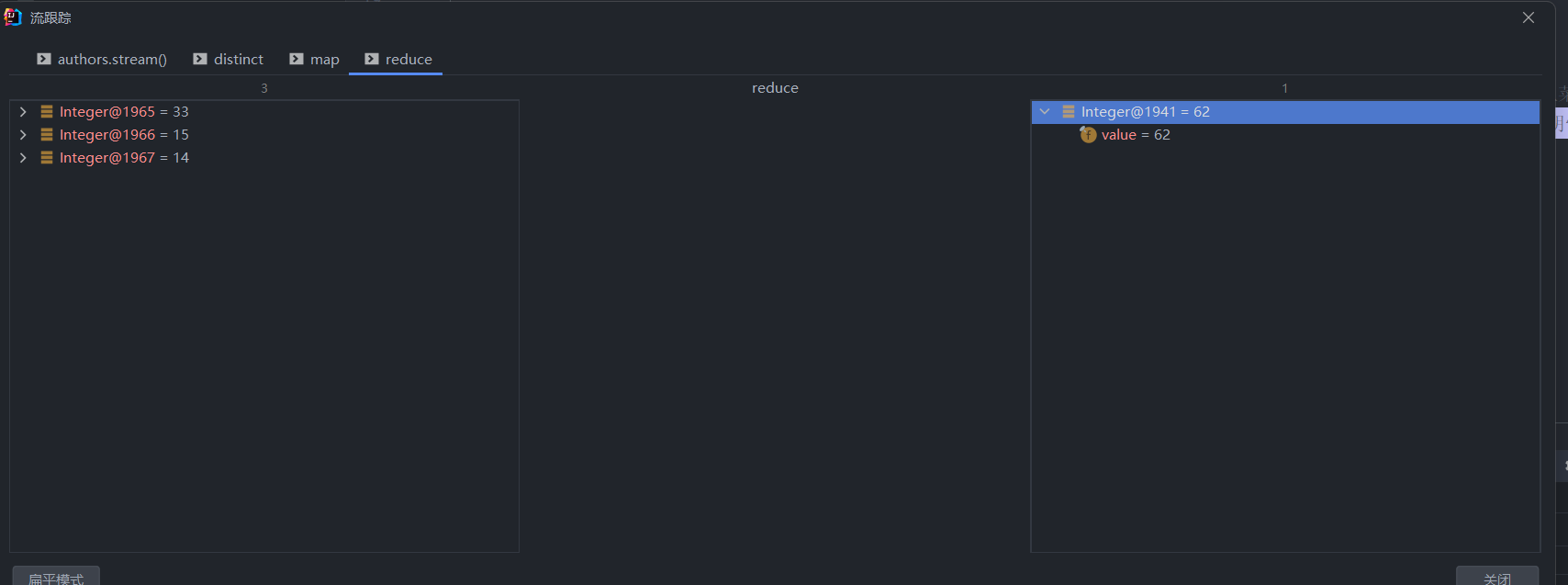
1
2
3
4
5
6
7
8
9
10
| @Test
void testrduce2() {
List<Author> authors = getAuthors();
Integer max = authors.stream()
.distinct()
.map(author -> author.getAge())
.reduce(Integer.MIN_VALUE, (res, element) ->
res = res < element ? element : res);
System.out.println(max);
}
|
注意事项

Optional
概述

使用
✨ 创建对象
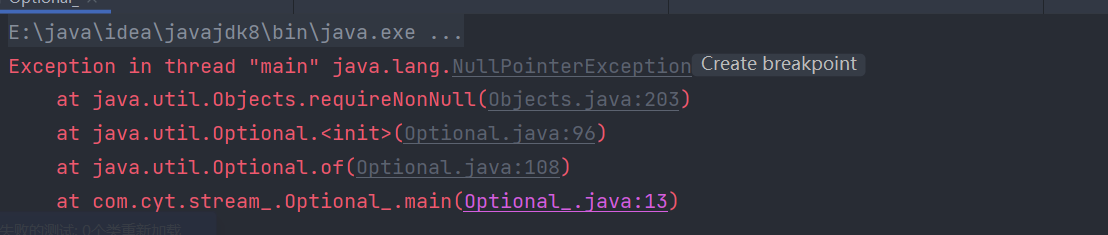
- Optional 就好像是包装类,可以把我们的具体数据封装 Optionalx 对象内部。然后我们去使用 Optional 中封装好的方法操作封装进去的数据就可以非常优雅的避免空指针异常。
- 我们一般使用 Optionall 的静态方法 ofNullable 来把数据封装成一个 Optional 对象。无论传入的参数是否为 nu 都不会出现问题.。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public static void main(String[] args) {
Author author = getAuthor();
Optional<Author> authorOptional = Optional.ofNullable(author);
authorOptional.ifPresent(author1 -> System.out.println(author1));
}
static Author getAuthor() {
Author author = new Author(1L, "蒙多", 33, "一个从菜刀中明悟哲理的祖安人", null);
return null;
}
public static <T> Optional<T> ofNullable(T value) {
return value == null ? empty() : of(value);
}
|
- 如果你确定一个对象不是空的则可以使用 Optionall 的静态方法 of 来把数据封装成 Optionali 对象。(不常用)
1
| Optional<Author> authorOptional = Optional.of(author);
|
✨ 安全消费值
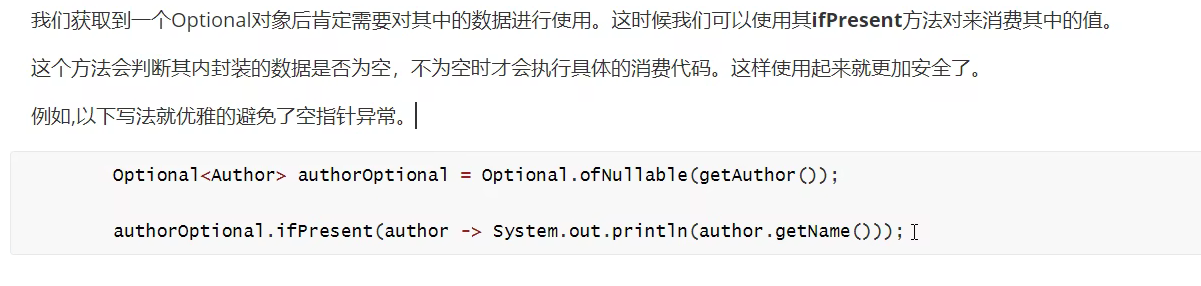
安全获取值
- orElseGet
获取数据并且设置数据为空时的默认值。如果数据不为空就能获取到该数据!如果为空则根据你传入的参数来创建对象作为默认值返回。
1
2
3
4
5
6
7
8
9
10
11
12
| @Test
void testOrElseGet() {
Optional<Author> authorOptional = getAuthorOptional();
Author author = authorOptional.orElseGet(() -> new Author(1L, "默认", 33, "默认", null));
System.out.println(author.getName());
}
static Optional<Author> getAuthorOptional() {
Author author = new Author(1L, "蒙多", 33, "一个从菜刀中明悟哲理的祖安人", null);
return Optional.ofNullable(author);
}
|
- orElseThrow
获取数据,如果数据不为空就能获取到该数据。如果为空则根据你传入的参数来创建异常抛出。
1
2
3
4
5
6
7
8
9
10
11
| @Test
void testOrElseThrow() {
Optional<Author> authorOptional = getAuthorOptional();
try {
Author author = authorOptional.orElseThrow(() ->
new RuntimeException("数据为null"));
System.out.println(author);
} catch (RuntimeException e) {
e.printStackTrace();
}
}
|
过滤

1
2
3
4
5
6
| @Test
void testFilter() {
Optional<Author> authorOptional = getAuthorOptional();
authorOptional.filter(author -> author.getAge() > 18)
.ifPresent(author -> System.out.println(author));
}
|
判断
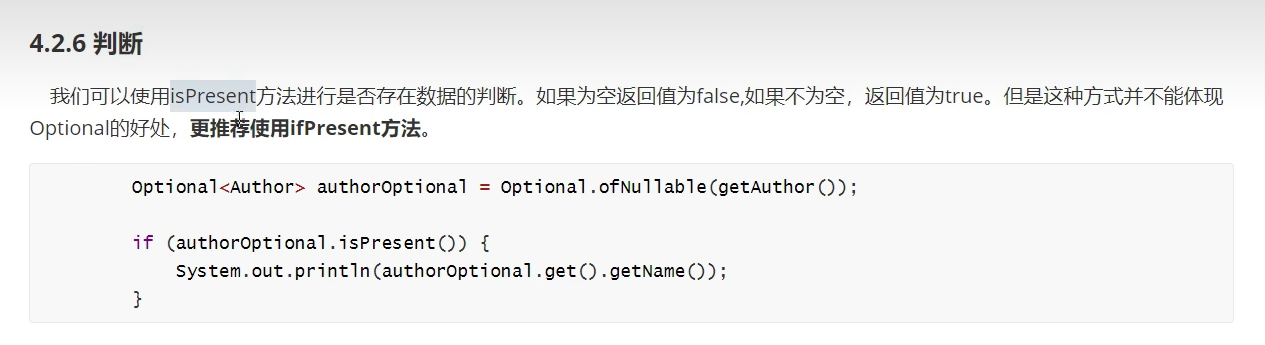
数据转换 Map
1
2
3
4
5
6
| @Test
void testMap() {
Optional<Author> authorOptional = getAuthorOptional();
authorOptional.map(author -> author.getName())
.ifPresent(name -> System.out.println(name));
}
|
函数式接口
概念
- 只有一个抽象方法的接口我们称之为函数接口。
- JDK 的函数式接口都加上了@Functionallnterface 注解进行标识。但是无论是否加上该注解只要接口中只有一个抽象方法,都是函数式接口。
常见函数式接口
- consumer

- Function

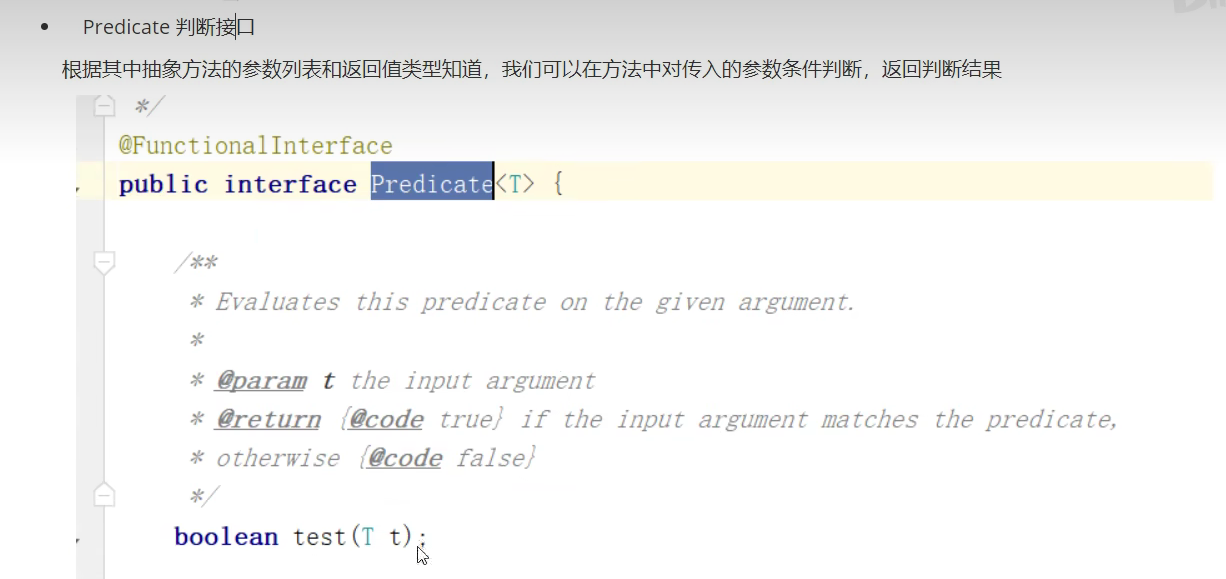
- Predicate
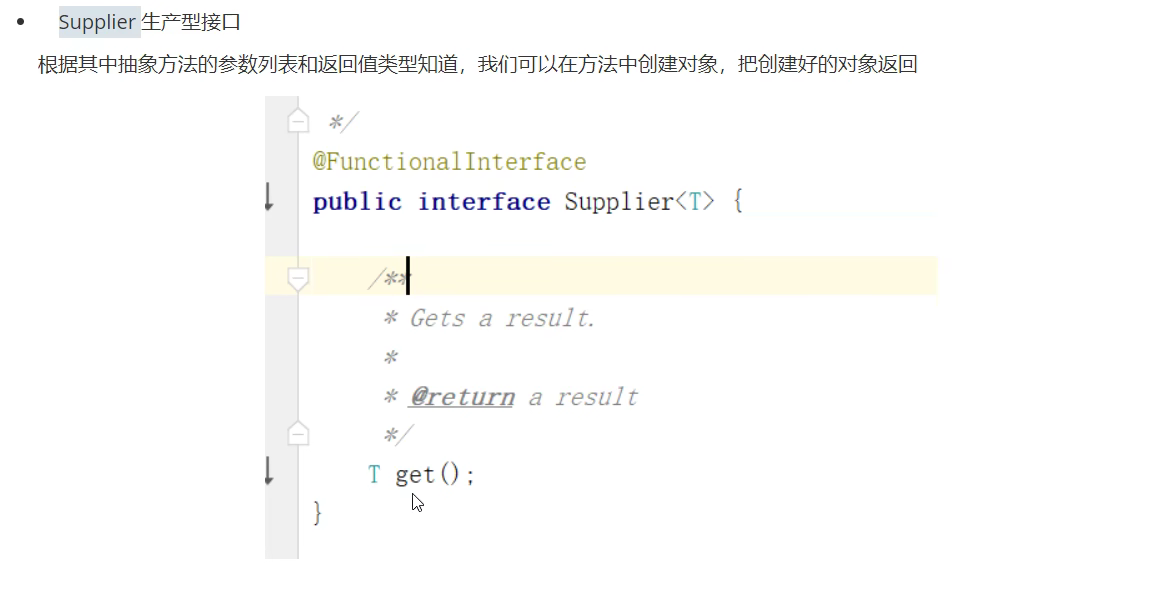
- Supplier
函数式接口常用的默认方法
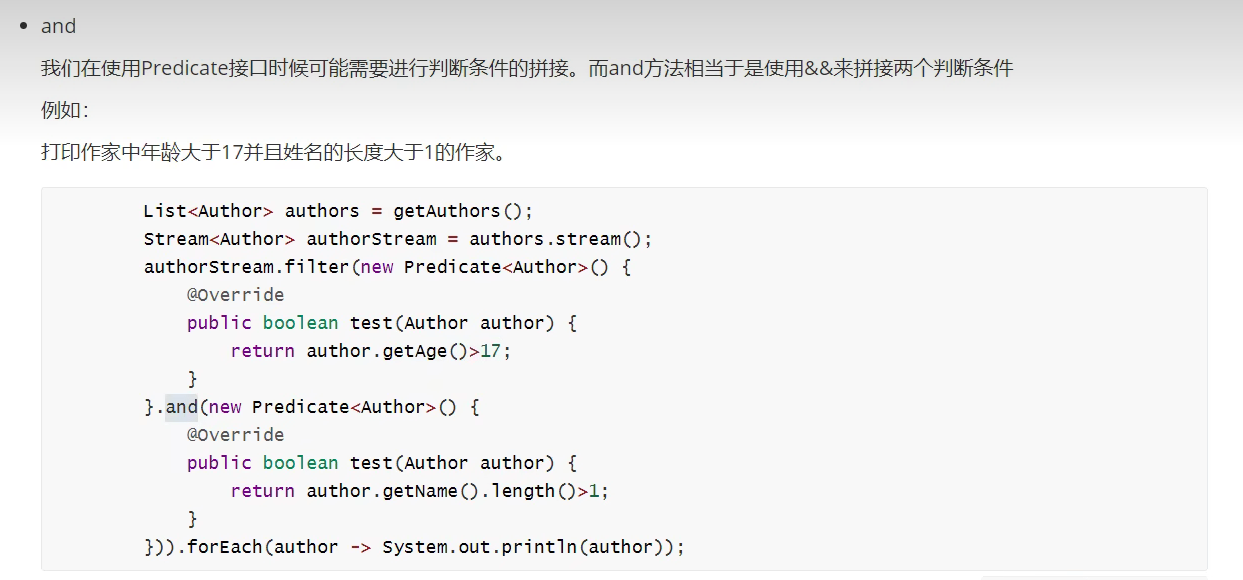
- and
- or
6.方法引用
- 我们在使用 lambda 时,如果方法体中只有一个方法的调用的话(包括构造方法),我们可以用方法引用进一步简化代码。
6.1 推荐用法
- 我们在使用 lambda 时不需要考虑什么时候用方法引用,用哪种方法引用,方法引用的格式是什么。我们只需要在写完 lambda 方法发现方法体只有一行代码,并且是方法的调用时使用快捷键尝试是否能够转换成方法引用即可。
- 当我们方法引用使用的多了慢慢的也可以直接写出方法引用。
6.2 基础格式

6.3 语法详解
引用类的静态方法
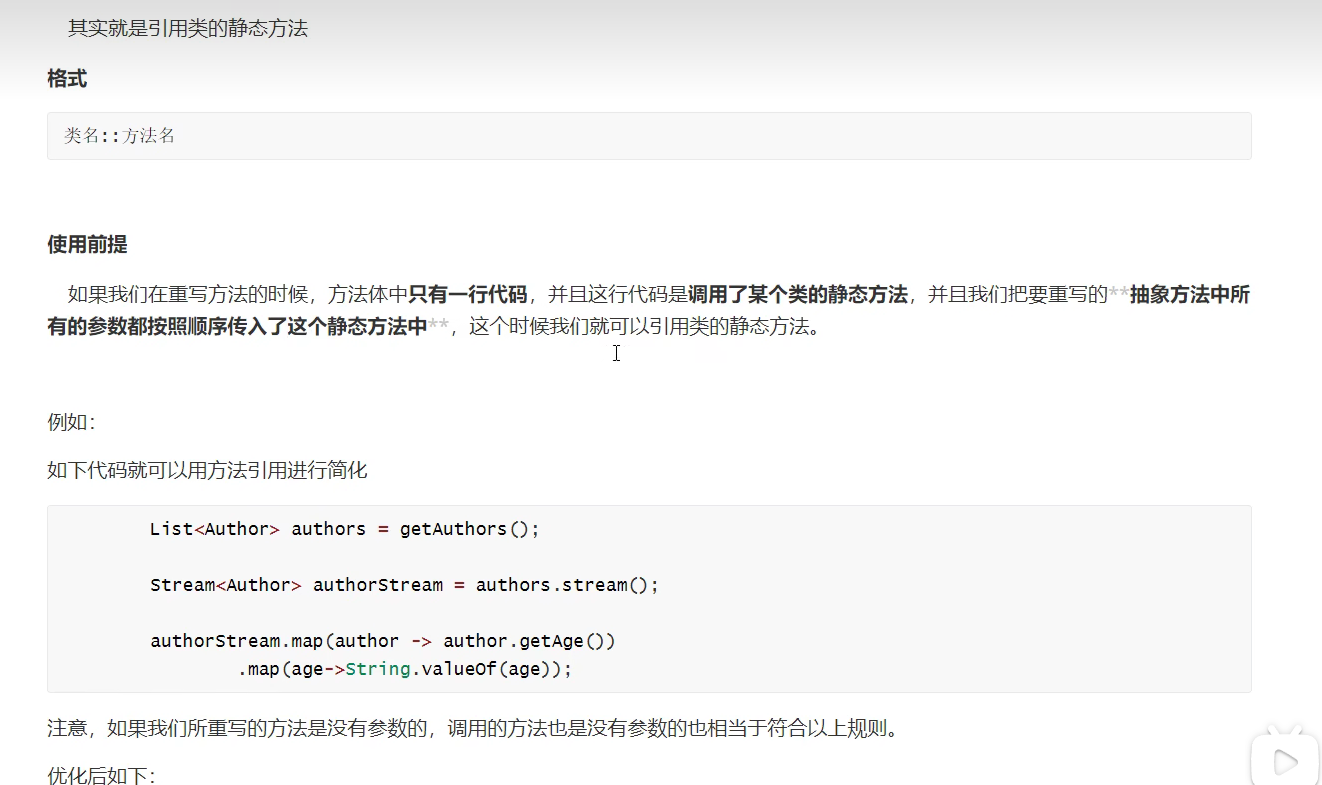
1
2
3
4
5
6
7
8
9
10
11
12
13
| @Test
void testJingTai() {
List<Author> authors = getAuthors();
authors.stream()
.map(author -> author.getAge())
.map(String::valueOf)
.forEach(item -> System.out.println(item));
}
|
引用对象的实例方法
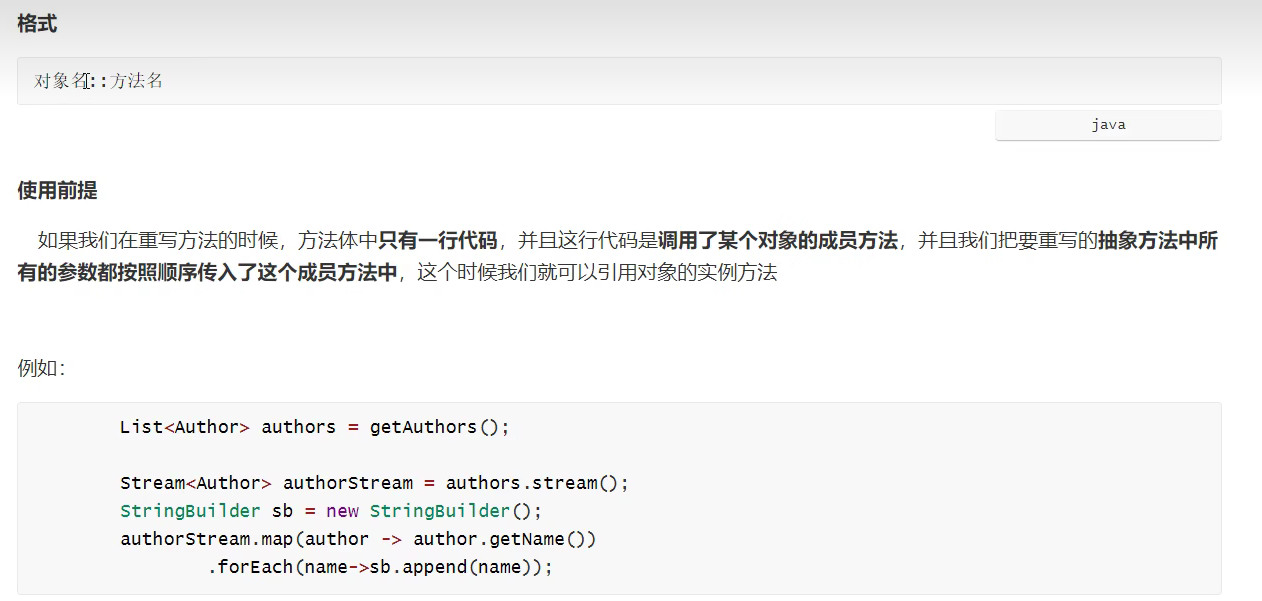
1
2
3
4
5
6
7
8
9
10
11
| @Test
void testDuixiang() {
List<Author> authors = getAuthors();
StringBuilder sb = new StringBuilder();
authors.stream()
.map(author -> author.getName())
.forEach(sb::append);
System.out.println(sb);
}
|
引用类的实例方法
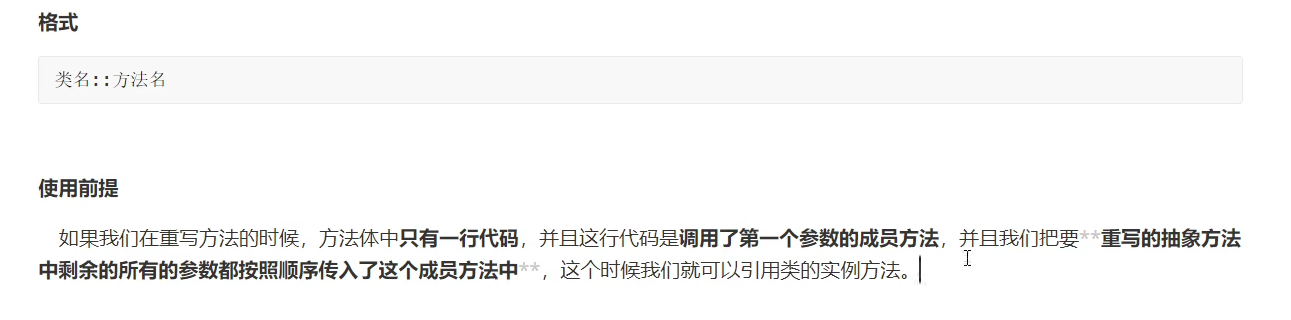
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class MethodDemo {
interface UseString {
String use(String str, int start, int length);
}
public static String subAuthorName(String str, UseString useString) {
int start = 0;
int length = 1;
return useString.use(str, start, length);
}
public static void main(String[] args) {
subAuthorName("cyt", (str, start, length) -> str.substring(start, length));
}
}
|
构造器引用
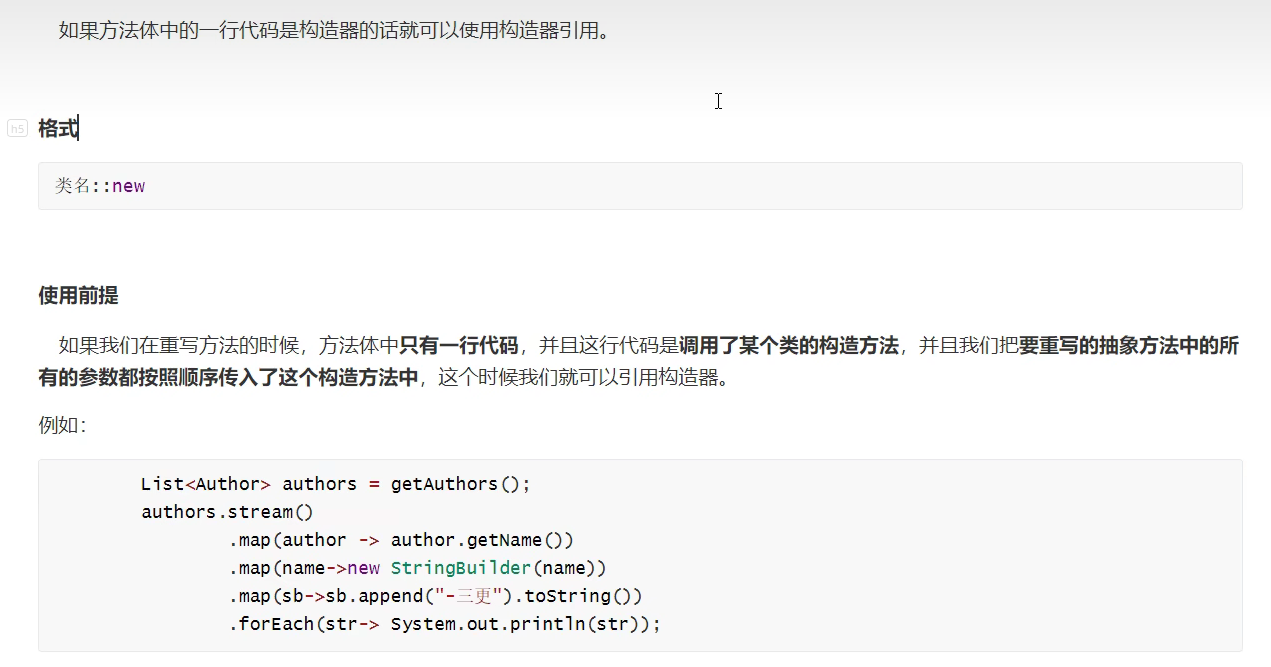
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| @Test
void test1() {
List<Author> authors = getAuthors();
authors.stream()
.map(author -> author.getName())
.map(name -> new StringBuilder(name))
.map(sb -> sb.append("-cyt").toString())
.forEach(str -> System.out.println(str));
}
authors.stream()
.map(Author::getName)
.map(StringBuilder::new)
.map(sb -> sb.append("-cyt").toString())
.forEach(System.out::println);
|
7.高级用法
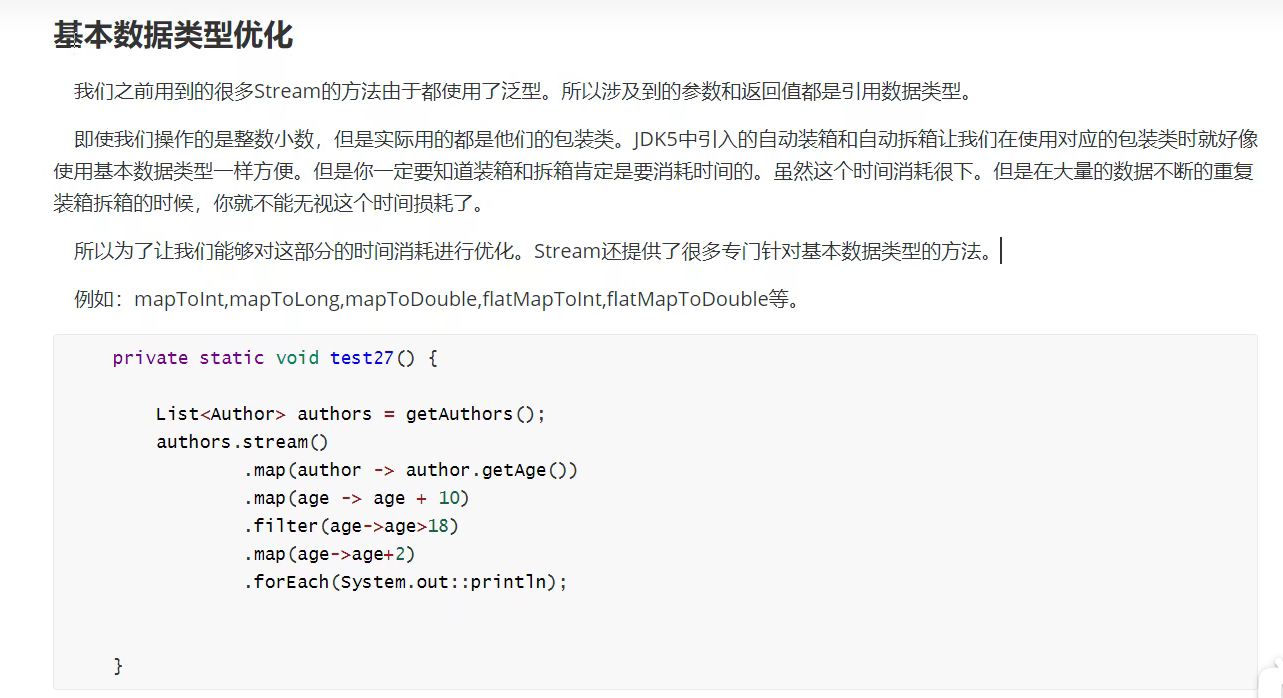
基本数据类型优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| @Test
void testGaoJi() {
List<Author> authors = getAuthors();
authors.stream()
.map(author -> author.getAge())
.map(age -> age + 10)
.filter(age -> age > 18)
.map(age -> age + 2)
.forEach(System.out::println);
}
authors.stream()
.mapToInt(author -> author.getAge())
.map(age -> age + 10)
.filter(age -> age > 18)
.map(age -> age + 2)
.forEach(System.out::println);
|
并行流
1
2
3
4
5
6
7
8
| @Test
void testJuc() {
Stream<Integer> integerStream = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = integerStream.parallel()
.filter(num -> num > 5)
.reduce(0, (res, ele) -> res + ele);
System.out.println(sum);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| @Test
void testJuc() {
Stream<Integer> integerStream = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = integerStream.parallel()
.peek(new Consumer<Integer>() {
@Override
public void accept(Integer num) {
System.out.println(num + Thread.currentThread().getName());
}
})
.filter(num -> num > 5)
.reduce(0, (res, ele) -> res + ele);
System.out.println(sum);
}
|
 微信
微信 支付宝
支付宝